
Everyone that works in software has seen the Joel Test at some point or another. Whether it was in a job application, or discussed, even complained about in the office. However, many might not realize that the Joel test was conceived of all the way in 2000. Its a true testament to its power that it is still discussed today. So much has happened in the world of software development since then. React, GraphQL, Docker, Ruby on Rails itself didn’t exist until 2004! So many transformative technologies have come since that time, so it would be natural to revisit something that is discussed so widely. In that spirit I came up with my own list, which shares a couple of line items from the Joel test but is mostly unique from it. Without further ado, here is my list for developer happiness:
- Do you automatically build after every approved PR, i.e. Continuous Deployment?
- Do you utilize best practices for source management?
- Do you log errors and monitor performance?
- Do you enforce best practices by linting your code and performing static analysis?
- Have you clearly defined testing responsibilities?
- Do you write tests before fixing bugs?
- Can your developers run migrations without worry?
- Is there at least 1 database for each separate service?
- Do you utilize feature flags, versioning or other techniques to facilitate deployment?
- Do you have a consensus driven process for product development and prioritization?
- Do you monitor and track the effectiveness of features?
Now I will breakdown each item and explain them in more detail:
Item 3 on the joel test asks “Do you make daily builds?” The first item on my list expands this by asking if you make builds whenever a pull request is approved. In other words, “continuous deployment”. Many companies struggle with continuous deployment, citing difficulties in stability and executing deployments this frequently, however, this usually is a smell for other artifacts of bad design within a companies infrastructure (see number 7 and 8).
The reason continuous deployment is such a key component to developer happiness harkens back to the lean startup model itself. Frequent small iterative changes can be more easily assessed. I cannot tell you how many times i’ve worked with other developers with incredible talent and ambition, but that lacked the discipline to see their features in an incremental way and be able to break them apart to smaller pieces.
This not only makes it easier to review and deploy, but makes it easier to pinpoint where production problems may be arising. I’ve spent countless hours digging through massive pull requests trying to isolate a single bottleneck that slipped through a PR; like finding a digital needle in a haystack. Its best to avoid this by working more carefully, deliberately and with better isolation and encapsulation in your design. If there is a feature that has you particularly worried on deployment, free yourself of that worry by wrapping it in a feature flag and making roll backs a non issue (see item 9).

Item one on the Joel test list asks “Do you use source control?” Its amazing to think there was a period of time where this was not a standard practice where today its almost a given. So I think it makes sense to expand the rule a bit to ask if in addition to using source control, if you are using it in the right way. What does this mean? In the first item we emphasized how continuous deployment on smaller encapsulated features leads to greater stability and ease of debugging. In order to facilitate this then it makes sense that you should do the following:
- Keep Pull Requests as Small as possible.
- Keep commits as small as possible, and commit messages descriptive.
This makes reviewing pull requests a much easier task for the reviewer, and reviewing a pull request is an important part of the process. I have been in jobs before where some pull requests were so massive that it got to the point that no one wanted to review them! In regards to pull request etiquette I’ve seen some really interesting approaches. For example, once I submitted a pull request and the reviewer responded by rewriting the pull request making it substantially more complex to read and even broke several of the tests! The reviewer has to realize while their feedback is valuable, the originator of the work is still the author of the pull request. Its always best to be curteous by trying to understand the original intent behind the pull request and asking questions of the author rather than try to replace their input with your own approach.
This expands the 4th item on the Joel test to include performance monitoring. These are more items that are so common place its hard to imagine a tech company without them these days. Services like New Relic have made performance monitoring much more common place to the point where every company I have worked with has used New Relic.
However, infrastructure monitoring has blossomed in recent years as well. Services like Datadog have made it possible to have a very close eye on instracture exceptions and monitor them with incredible accuracy. These oversight tools have made it to the point where many companies have even taken an extreme mode of working solely from these metrics coining the term Metrics Driven Development, even abandoning tried and true methodologies like Test Driven Development. Personally, I cannot imagine a world without tests keeping things in line, but for some companies the scale at which they work makes maintaining test suites of that size a practical impossibility.
I can’t describe the relief I had on the day that I integrated RuboCop and Brakeman as blocking parts of my last companies continuous integration scripts. No longer did anyone have to constantly remind one another of little violations in best practices, we just had to update our rubocop yml and rubocop did all of the heavy lifting. Once people started noticing that the tests were failing remotely, they started running them locally before they pushed up their pull requests. There were some that thought it was over the top, but in the end it saved so much time in automating the enforcement of best practices.
In the Ruby world, Brakeman can never replace common sense and careful coding around security practices and keeping a keen eye on CVE but still is better than no automated security testing and thus provides a considerable amount of value as well. If you like this approach, other tools like Pig and Bullet can even seek your code out for grevious violations in performance design.

Item 10 on the joel test asks “do you have testers”. I found this a little odd the first time I read it. About 50% of the jobs i’ve experienced in the past thought of testing as solely the responsibility of the engineers. While personally, I find this is not an ideal practice, because the engineers the wrote the code are in fact the worst people to test it (because they are predisposed to think about it in the way they wrote it, thus missing major mistakes), the fact remains that many companies still make engineers do the majority of the testing as a way of keeping them accountable for their own work. Therefore, I decided to make this item less specific and simply ask if testing responsibilities are clearly defined and understood in the company.
This also includes the company establishing best practices about automated tests. Does the company use request, controller, and session specs and not BDD such as capybara or selenium? This is fine as long as the company comes to a consensus together about how they should approach testing and whether or not they will bring in additional head count to deal with functional and usability testing.

The Joel test asks in item 5 if you fix bugs before writing new code. While this is important, I think it falls more under an implicit activity that arises from logging the errors and monitoring them. However, one practice seem ubiquitous in debugging bugs and that is writing tests. So many drawn out conversations I’ve had in the past could have been avoided by one small request “Could you send me a failing test to describe the issue you are describing?” I came to the point where I almost found it easier to communicate at times through tests rather than through English. The effectiveness of the approach is emphasized by the fact that Rails makes it a required practice for submitting issues. While getting 100% test coverage is not always a sensible goal, approaching bugfixes with a test first mentality seems like a no brainer.
This one is huge. If the relational database is overloaded in throughput in such a way that certain tables are locked out from being migrated upon this creates a huge obstacle for developer productivity. While certain types of migrations such as renaming, altering tables, or reindexing are fundamentally difficult to perform and should be forgone in favor of techniques such adding new columns and deprecating old ones, the fact remains that if migrations are a tenuous and difficult process then your developers are going to be hesitant to add them.
This ties somewhat into Continuous Deployment which becomes more difficult if migrations are an obstacle especially in a strict zero downtime environment. Features like InnoDB’s online DDL for MySQL can help with this, but nothing can replace have a very robust and well architected microservice design and multiple databases for different responsibilities. This eliminates the database as a single point of failure, and accommodates differing velocities of data

In the previous point I linked to a wonderful GoTo conference talk by Fred George that describes how to approach microservice design. I would recommend watching this entire video, Fred George is a pioneer and every minute of this video is a goldmine. In it he describes how many companies make the mistake of having a single underlying database (often relational) even when they have several separate services. This single point of failure becomes an obstacle to the overall ecosystem of the company and should be avoided at all costs.
The reality is that each service should serve a distinct purpose (a telescoping of the Single Responsibility Principle of OOP), and that it may demand one or several different database technologies depending upon its function and goal. While ETL processes might be needed to keep separate services in sync, keeping a single massive underlying database as a single point of failure becomes a huge bottleneck as you begin to scale your system. For more information about the many database design and its biological inspiration watch this really awesome talk (also a GoTo conference video) by Chad Fowler.
In point 3 I mentioned Metrics Driven development and how so companies utilize this in lieu of test driven development. While I don’t endorse this approach, the only way I would recommend it if it were in conjunction with some way to wrap risky features in feature flags. Deployment rollbacks simply put are time consuming, risky, difficult to pull off without event and if you can avoid them you almost always should. In companies that do not have a good microservice and database design deployment can become a challenge. I had the unfortunate experience of working in one such company in the past. When a separate dev-ops team is handling deployments, the back and forth becomes prohibitively challenging. I found over time that it was in fact easier to wrap risky features, features that I thought might cause some type of problem in feature flags which I could then activate or deactivate at my leisure.
As time went on I found that this tactic in fact worked as a solid practice in general and started doing it more often. After all, a deployment might take several minutes, but flipping a feature flag in a relational database takes milliseconds. This is not a universal solution, for example, changes that complect the object design destructively could not be safely added to a feature, however, many features that are more additive or even configuration oriented become a good fit for protection behind a feature flag. Not only this, but it also becomes a good way to approach AB testing to the point that one company LaunchDarkly built a business model around this approach. Separating some features from deployments only further increases the feasibility of continuous deployment and makes your deployments more stable.
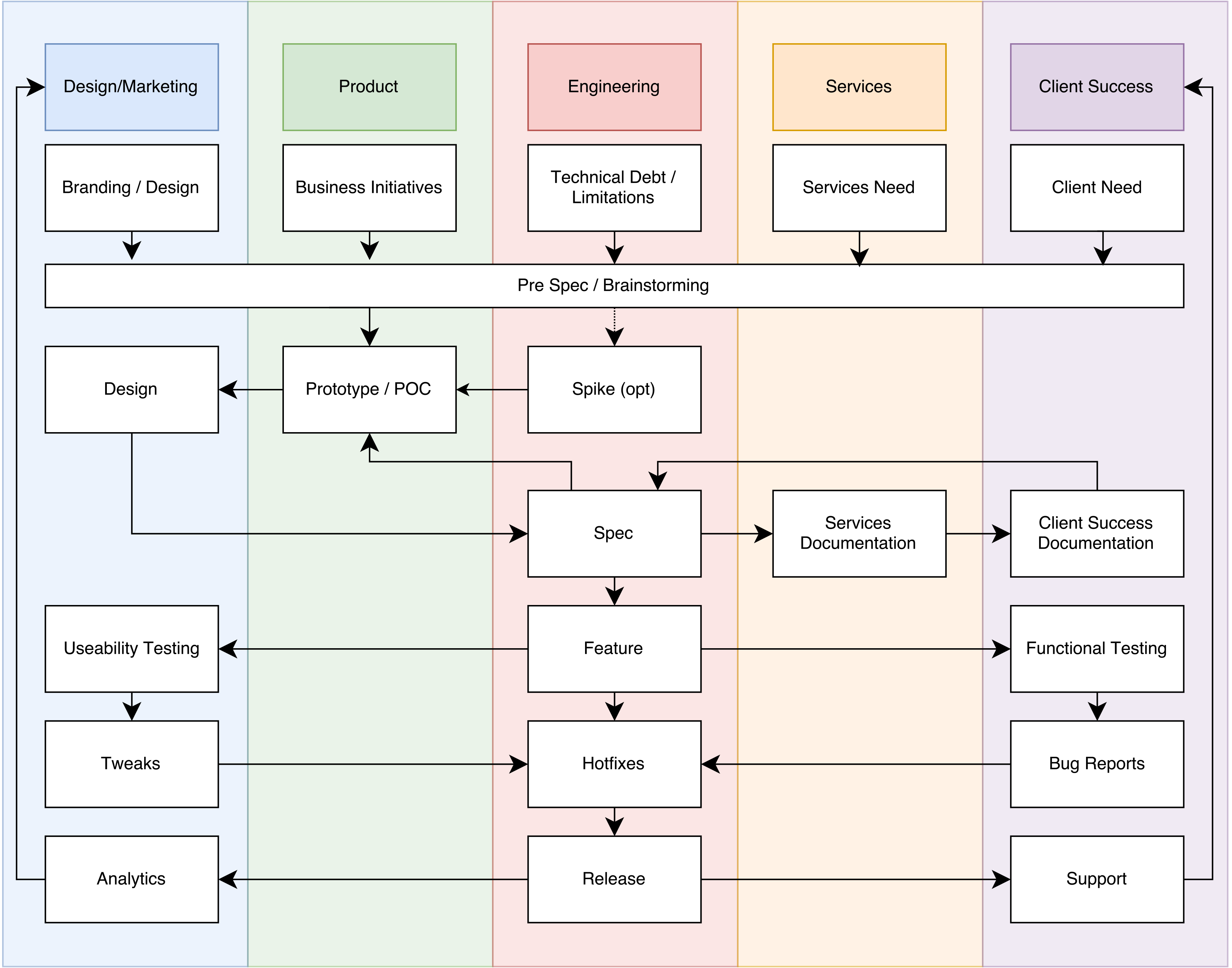
In this blog post I describe a consensus oriented product development life cycle. Why is this important for developer happiness? Because the worst thing that can happen for a developer is for them to pour their heart into a feature and for the company to shift directions and abandon what they have worked so hard on, of no fault of their own, simply because of the shifting priorities. This is extremely frustrating to developers and while it is inevitable, it should be avoided at all cost. Make sure that every stakeholder has signed off on a feature before development begins and make sure that your feature has been driven through a process of consensus building on it before work begins to avoid developer frustration about shifting priorities.
In the same blog post I reference in 10 I describe how monitoring of features is an essential part of a good product development lifecycle. Why is this important to developer happiness? Because it provides feedback and validation to their work as being effective. This is absolutely essential to provide developers with the motivation they need to keep working and building tools that they think will make a lasting impact on the company and the broader development community (in the case of open source).
Enjoy this list and let me know what you think. While not every item is required, the more you have, the more productive, happy and purpose driven your development team will become.
Kyle Prifogle