
This theory goes something like this:
OpenAI opening up their api will result in the internet being flooded with ChatGPT content.
ChatGPT cannot actually tell if content is written by itself, especially short form content, 100% of the time.
ChatGPT in order to be retrained must now train on data that it produced itself. There will be an attempt to filter out generated content, but the training process will inadequately identify generated content and not be able to do a good enough job of this. We will in fact discover that in a lot of scenarios its impossible to distinguish generated content from real.
This will create strange artifacts and behavior in ChatGPT, how this plays out exactly I’m not sure. Open to suggestions on how it starts to decohere. This is the key point to discuss. The outcome could be much more severe. Can ChatGPT succesfully train on its own generated data and continue to progress? Will the outcome of this be decoherence, hyperbolic exageration of certain behaviors, or something else, maybe even evolution/progression? This is a classic feedback loop either way.
We will have no choice but to only train ChatGPT on versions of the internet that existed before OpenAI made their API’s publicly available. Hello Internet Archive!
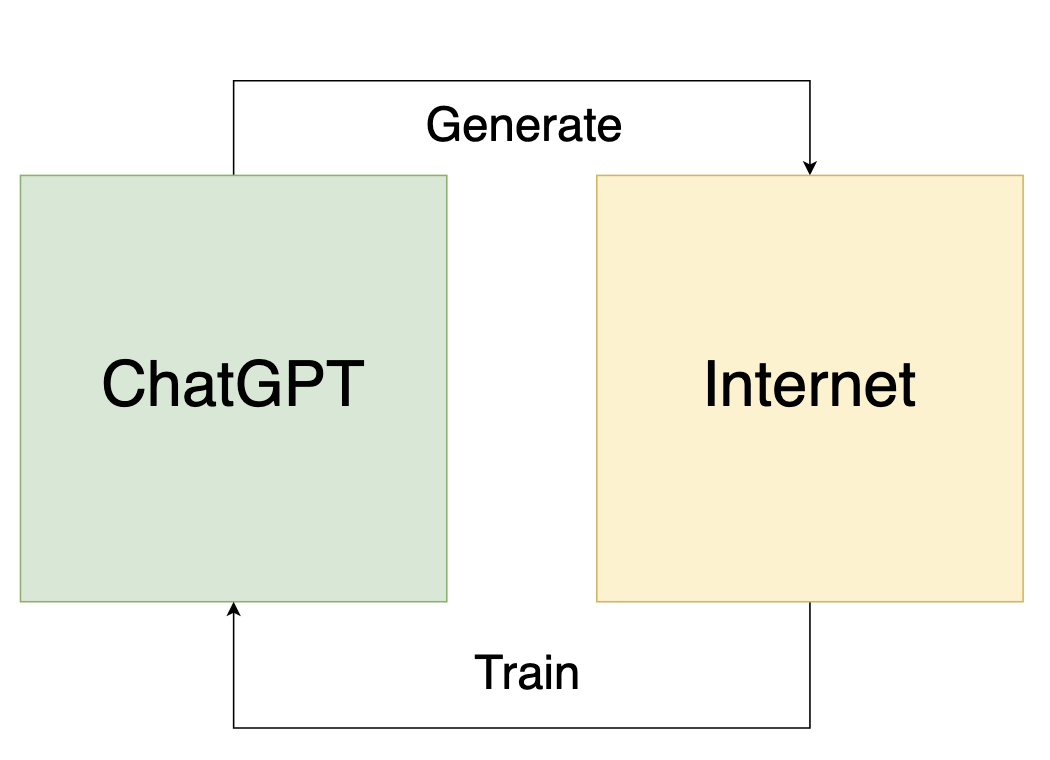 Will the feedback loop be constructive or destructive?
Will the feedback loop be constructive or destructive?
There are some ways OpenAI can attempt to mitigate this issue, such as somehow encoding a signature into generated content that indicates that content is generated, but this is ultimately an arms race scenario and it will be a constant battle to fight ways to forge or bypass that functionality.
The end result is that ChatGPT will be stuck in this day and age forever. If this theory is correct enjoy it while it’s current! It will soon be stuck in a time capsule.