
Its a pattern that we know all to well because we see its presence emerge naturally overtime in the companies we work at. Companies organizing their technology to be complementary in such a way that supplements productivity and uses the right tools for the right job. Javascript in the front, ruby in the middle java in the back. Or maybe javascript in the frontend, python in the middle, C++ in the backend. The reasoning for this type of organization is usually a combination of culture and hiring conveniences, and because those technologies happen to complement one another in particular ways, but have we stopped and really thought about specifically why this type of structure has emerged over time? An interesting answer to that question comes in thinking about the specific characteristics of those languages and their strengths and weaknesses in the context of a concept I call “churn”.
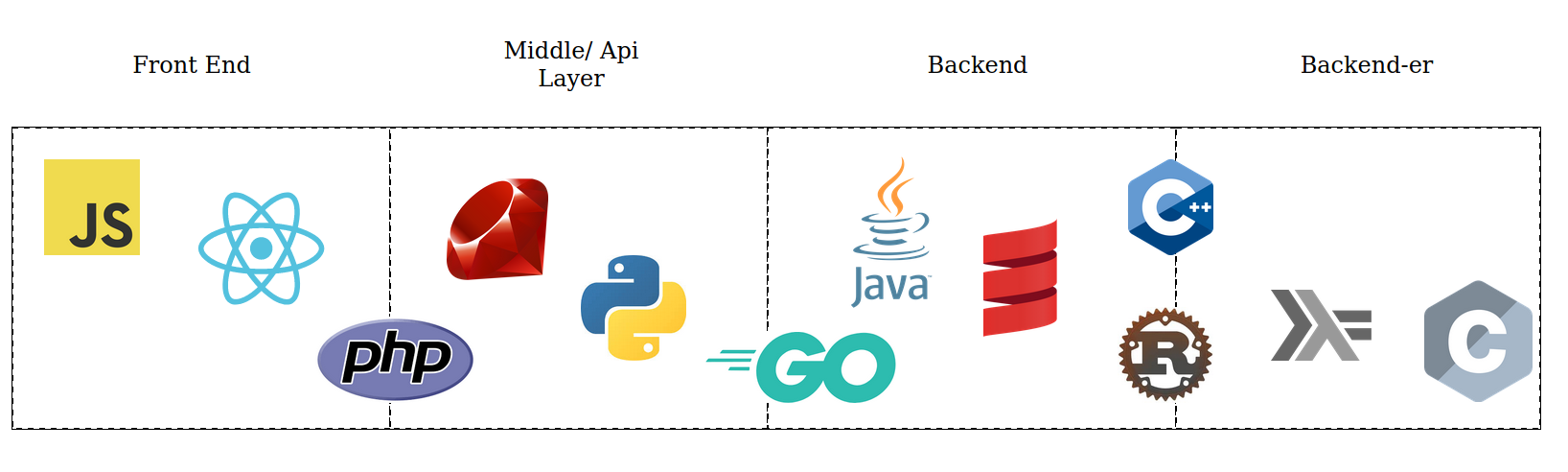 Note: This diagram is deliberately a stereotype, think of it as a projection along the dimension of churn.
Note: This diagram is deliberately a stereotype, think of it as a projection along the dimension of churn.
Before I go further I should explain what I mean by “churn”. Churn is a terminology I have borrowed from marketing that is typically referred to as “customer churn” or the rate of change with which customers turn over. In the context of software systems I refer to churn as meaning more generally “rate of change” within a software system. You can think of this as the churn rate of the code, but it also can refer to the rate of change of the use cases, configurations, and business systems surrounding the code itself. In essence it is the rate of change imposed by external systems, end users, business requirements on the desired software system to solve that particular business problem.
Thinking about the previous “classic enterprise architecture” in this context presents some interesting ways of viewing the phenomenon. You start to see that on the edges of the software system where it is interacting with external systems (typically end users), there is more churn in the system, and that we compensate for that greater rate of churn by adopting languages and paradigms that are more dynamic and ammenable to that higher rate of change.
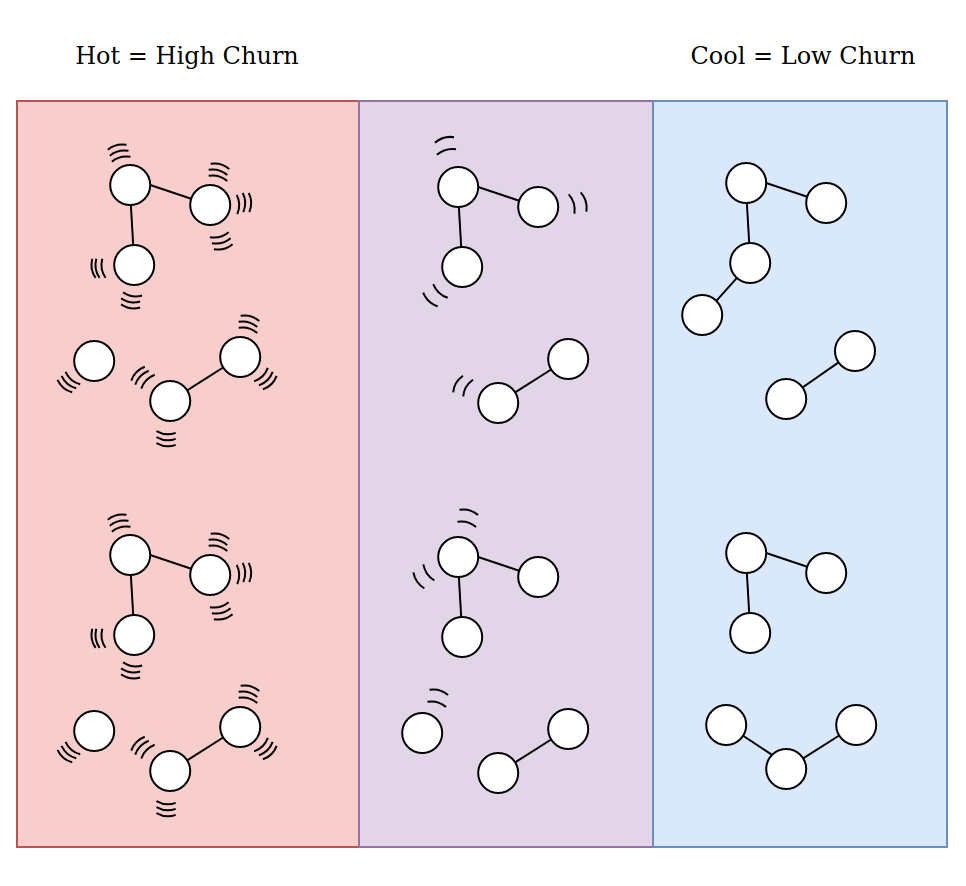 Churn in analogy to thermodynamic entropy
Churn in analogy to thermodynamic entropy
One way to think about this is in terms of entropy of heat in materials engineering. You design materials to accomodate the highest heat rate on the outside then gradually develop different layers of materials with other desirable characteristics that need to be more insulated from the heat going gradually internal to the material. Another analogy that I use alot when thinking about designing reactive systems to be able to handle a large amount of data is thinking about traffic patterns, off ramps, speed zones as various tools you can use to take a heavy amount of traffic and gradually start to siphon off parts of it until you have distributed a manageable amount of traffic to the right places. Yet another analogy I use in this regard is that of water sluiceways and how they are used to prevent floods. You get the idea, but long story short the same analogy can be used here substituting “traffic volume”, or “water volume” for “churn volume”.
This is the part of the argument where I get a bit controversial but not without a point. I argue that each language and its accomponying libraries, ecosystem and even the culture surrounding that language has very specific strengths that should be capitalized on. Its when we start to think of a single programming language as having “universal appeal” that we start to get into trouble. No offense to the node.js crew as this is purely my perspective and personal preference, but I cringe a bit when I think about designing back end systems with javascript. Typescript emerged on the scene and made that prospect a bit more sensible, but to a large extent typescript is just an attempt to extend the language to capitlize on a particular strength that it was not designed to have in mind, perhaps at the mercy of abandoning its key historical strengths. You could probbably make the same argument in reverse about scala.js or other attempts to introduce generic or dynamic programming to strongly typed languages when maybe the best thing to do is to embrace the dynamic nature of the underlying thing you are trying to model instead.
This is where I come to my recent experiences with Formation.ai and some of the insights that I have had recently around its architecture. Formation is an amazing and challenging place to work for a number of reasons, and if you are a data engineer I highly recommend it. The main kind of defining feature of Formation is that it has been seeded from the beginning with ultra brilliant often times phd level practitioners of functional programming. While simultaneously Formation also finds itself at the extremely churn-filled world of online marketing as it builds incredible reinforcement learning inspired customer loyalty programs for major brands that are bleeding edge and deliver tremendous value. The difference between these two worlds is tremendously challenging and produces some amazingly novel concepts.

A main desirable characterstic of functional programming is that it allows you to define extremely safe maintainable software systems. Systems that you know exactly what they are doing at any given moment. This is an over simplification obviously but relative to other approaches there is a kernal of truth here. However, one aspect of functional programming that makes it challenging is that it generally takes longer to build systems that are designed to be purely functional. I’ve had many conversations with my collegues and I realize that this is also an oversimplfication, and in their perspective perhaps a straight falsehood. They would argue, and I think this is completely valid, that for someone sufficiently experienced in FP it actually takes less time to implement systems with a pure FP approach than any other approach and that you get the added benefiets of pure programming as a bonus. The key phrase there is that it takes “someone sufficiently experienced” to be able to implement such a system, which if you look at the average of all the individuals that you have available to your hiring pool, and the amount of added implementation time added for lesser experience it averages out to a longer amount of time to implement than say throwing together a quick python script. And thats totally fine because you get so many added benefiets from FP that its often time worth the investment.
However, lets consider the aspect of churn that I brought up before. Imagine if you start to model a particular type of relationship you observe in the business patterns and develop the FP algebra that models that relationship over the period of a week and implement its requisite categories using a very pure FP approach only to find that within that week those relationships have fundmanetally changed or been abandoned altogether multiple times. In general, we find that the business world wants to move faster than the engineering world. That impendence mismatch is well known to us all so needs to be respected. Then the challenge becomes that (going back to the entropy analogy) given the business operations are “hot”, how do we arrangement our materials (layers of software systems) in such a way to best accomodate that reality and insulate systems that are less engineered to accomodate for that high rate of churn but have other characteristics such as maintainability which we desperately need if we are to succeed long term.
 Credit: Toggl engineering team
Credit: Toggl engineering team
Notice here that my argument is less that you can’t build an entire software system from the front end all the way to the back end in a single language (such as haskell, or on the other end javascript), but that sometimes doing so might be extremely impractical. Another way to put it is, if certain languages and paradigms require you to invest heavily in them, then it may make sense to be more choosy about when you chose to implement them, ie, dont use quantum mechanics to tie your shoes, and conversly, don’t try to use the bunny trick to trap an ion.
When developing the pilot architecture for Formation, we wanted to respect this concept of “churn”. As we anticipated given that many of these systems were pilot programs, they would be changing very rapidly and often times with little notice. As a result we sat back and took stock of the assets (both people and code) that the company had accumulated to that point. The company is a good mix of front end engineers (primarily javascript developers), data scientists (primarily python developers), data engineers (scala and python developers as well as SQL guru’s), and functional programmers (type level scala developers and haskell developers). Over time the company has moved in a direction to embrace for every time a more polyglot attitude which is good, but the remaining kind of core competencies remain. So given that set of assets at our disposal what type of system could we develop that respected the heavy “churn” idea. The following is what we came up with:
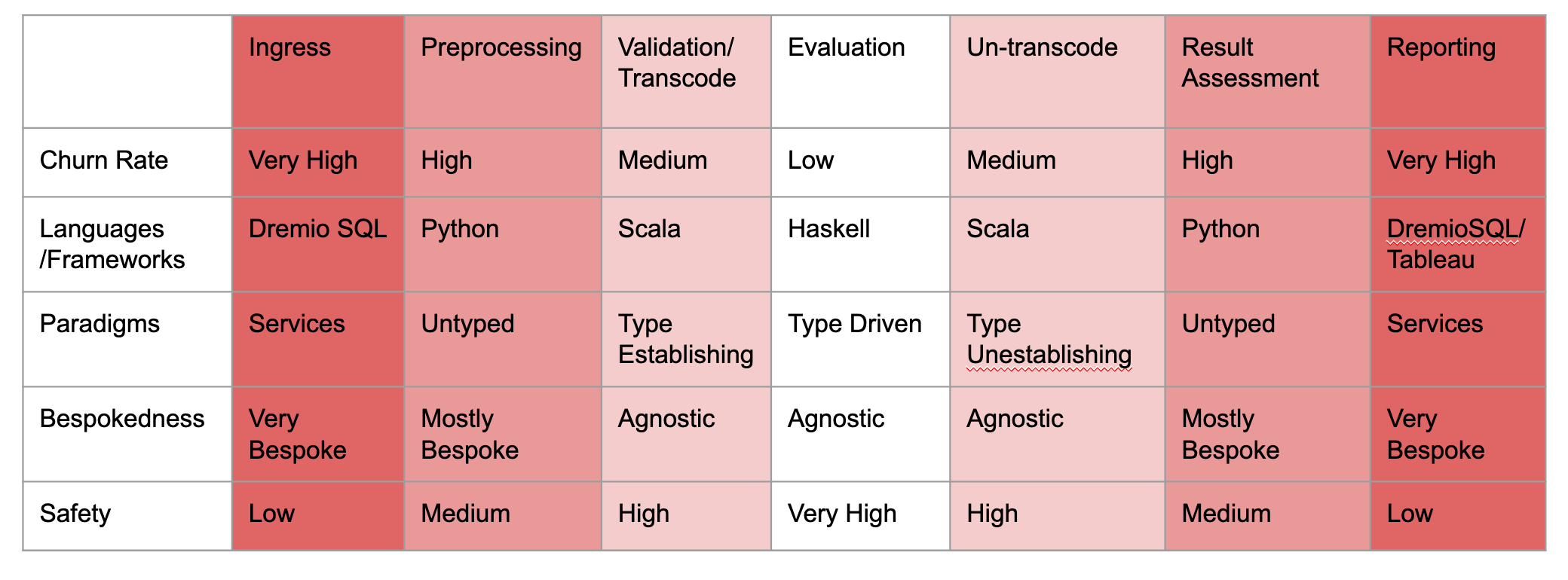
Notice a key aspect of this architecture is using SQL as what I call a “data configuration” language via means of Dremio. Dremio for those who aren’t familiar is a tool based on Apache Arrow and Apache Calcite that allows you to use SQL to specify virtual data tables which you can then access via means of JDBC for example to use in other Spark pipelines (for example). Think of it as a competitor to Presto with a materialization framework for external views and a snazzy front end with the ability to read from multiple types of data stores other than s3.
Its an interesting tool, that seems to be exactly the “right tool for the job” in this particular project, despite its lack of maturity around things like having a seperate persistent metadatabase that you can interact with directly (unlike hive), which we were able to get around by building a migration tool in scala that pulled the metadata into version control using the Dremio rest api. This allows Dremio to serve as the outer most, most flexible layer of our system, the one thats is most exposed to churn and is allowed to be deliberately client bespoke. What this allows us to do is massage the data into “canonical” tables which the rest of the system can use and dramatically siphons off a signifigant amount of churn. The other thing it allows us to do which is really intersting is defer product decision making until we have a statistically signifigant pattern emerge around our clients. In essensce Dremio becomes our product feature hopper, which we dig into and pull components from and develop later as we start to see patterns emerge in the Dremio queries between clients.
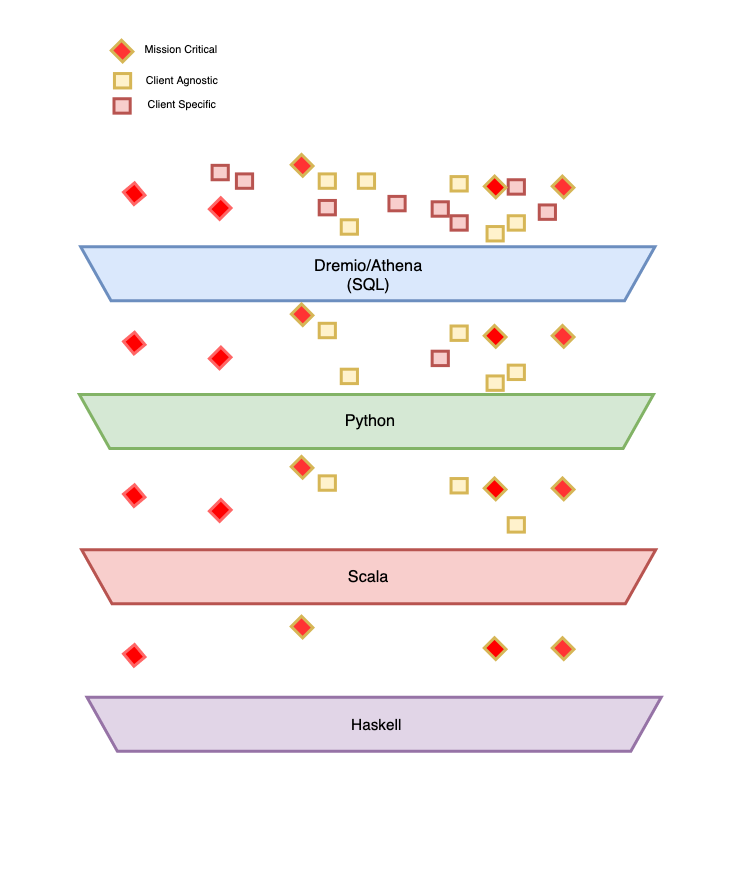
From there you can see the continuum from the very high churn Dremio SQL configuration layer down into the datascience which is still dynamic and flexible but requires more rigorous process around developing, down to the data engineering which is more type safe and written in scala and heavily leverages the canonical tables to prevent the code from having to change very much, all the way into the haskell layer which could be completely application agnostic and more “core” operations which don’t need to change constantly but need to be ultra safe and maintainable. I argue that this particular arrangement of using the right tools for the right job is both intuitive and puts the right pressures in the right places so that the company can operately at maximal efficiency in light of the highly churn based environment it finds itself in. Notice that the symmetry of the pattern of low to high churn exists even on the egress side of the fence where Formation has to configure sometimes very bespoke measurement metrics and guidelines to prove attribution of their value proposition. Basically any time the system is exposed to an “end user” or “non specialist user” of some sort we see these layers of churn insulation (going back to the thermodynamic analogy) emerge towards that eventual end goal.
Its also interesting to note how this parallels many of the data strategies that we’ve seen emerge over the years that goes from very unstructured data to highly use case specific structured data. In our case also the fact that we are using a data virtualization tool which helps to aleviate some of the heavier ETL that would be involved in such a data pipeline. The fact that Dremio is a distributed technology also means that it can scale to most our use cases in the batch realm within acceptable SLA’s (barring the complexity of reflection management which can sometimes make the SLA’s a bit more dicey). In our case we use it as part one of a one two punch for scalable data processing, the second being Apache Spark. Basically most use cases of Spark SQL we have moved into Dremio as its a tool that allows non specialist to query the data without having to know python or scala. This is really useful for things like debugging, QA and validation teams.
One note of caution, Dremio is still a green tool, and has its fair share of problems, particularly around materialization scheduling and handling. We realized after the fact that we could likely get the same type of behavior out of AWS Glue Data Catalog and Athena (Spark’s ability to point its metadata at the hive metastore-glue underlying athena is especially convenient) to handle the “services oriented metadata specification”, with some additional work around specifying certain views to be maintained as materialized views for quicker access. Moving forward this is likely what we will use in place of Dremio. A similar tool with alot of promise is being developed by LinkedIn called Dali which seems to be solving a similar problem as well, though its not yet open source. Another alternative could have been something like zeppelin or Databricks notebooks but it still would limit the users to people knowledgeable of python or scala. Deltalake SQL could have helped here but databricks overall felt like it was too disruptive to introduce at the time and still wasn’t quite as user friendly to non programmers.
To summarize I want to discuss various types of complexity in software engineering for data systems. There are 3 broad types of complexity here that I would like to shed light on as a result of this architecture, the third being perhaps the most overlooked:
System Complexity (internal complexity): This is what we typically think of when we refer to complexity in software. In general, how well does the software function on its own when no external forces are changing it or exerting pressure on it, ie how well does the software do its job. How well does it deal with volume, throughput, reliability and stability, latency. How easy is it to provision and maintain the infrastructure to run the software.
Operational Complexity (external complexity): This is some of the types of complexity we refer to when we say complexity in software but not all of it. This essentially is how well does the software cope with external business processes and change. How easy is it to extend the software and evolve it over time. How easy is it to configure. How easy is it for users to get analytic or diagnostic information out of the software. Churn as it pertains to business configuration falls into this category and the concept Churn Based Programming focuses a light on this type of complexity.
Social Complexity (meta complexity): This is the most overlooked category and its the type of complexity that comes with the fact that programming languages are maintained by people that have social structures that either reinforce or tear apart the use of languages. Things that would matter here include categories such as rate of adoption of a language, which is impacted by how comprehensible it is for a new learner. How fluid development in the language feels. What types of IDE’s or other development tools exist to be productive. What are the written or unwritten dogmas surrounding a particular language and how does that impact intentionally or unintentionally the proliferation of the use of the language. What are the interests of the community surrounding a particular language historically. For example, python and data science, javascript and front end development. Churn Based programming pertains to this type of complexity in the sense that it encourages certain types of languages with profiles of social complexity to focus on problems well suited for that community rather than attempt to be a universally applicable. IE, it embraces the diversity and strengths of programming languages.
I will end my discussion here as its starting to get long, but I hope that Churn Based Programming is found as a useful concept that others will draw inspiration from and try to find other more formal ways of expressing it. I’m eager to learn of more obvious or orthodox expressions of the same idea. In my next post I’m going to continue the discussion about programming languages and talk about the dueling concepts of Cohesion and Coupling and how it affects certain aspects of what programming language you might chose for a particular task, and think about those ideas in the lens of program churn.
Kyle Prifogle